LLMBoost Speedup
LLMBoost delivers industry-leading inference performance across a wide range of models and GPU configurations. Our benchmarks demonstrate significant speedups over alternatives like vLLM.
These benchmarks are updated weekly with the latest performance data across various hardware configurations and model architectures.
LLMBoost vs vLLM: Throughput Speedup
The table below shows the generation throughput speedup factor (LLMBoost tokens/sec ÷ vLLM tokens/sec) for each tested model and GPU combination, sorted from highest to lowest. Higher numbers indicate better LLMBoost performance.
LLMBoost vs vLLM: TTFT Latency Speedup
How much headroom does your SLO actually have? We ran a production-realistic benchmark following the MLPerf methodology, using a strict P99 TTFT < 2 seconds latency target. The reported speedup (vLLM avg TTFT ÷ LLMBoost avg TTFT) quantifies how much faster LLMBoost responds under identical traffic conditions across 10,000 prompts.
Based on the results in the table below, LLMBoost maintains the target latency, while vLLM exhibits significant degradation in TTFT and tail latency under the same load.
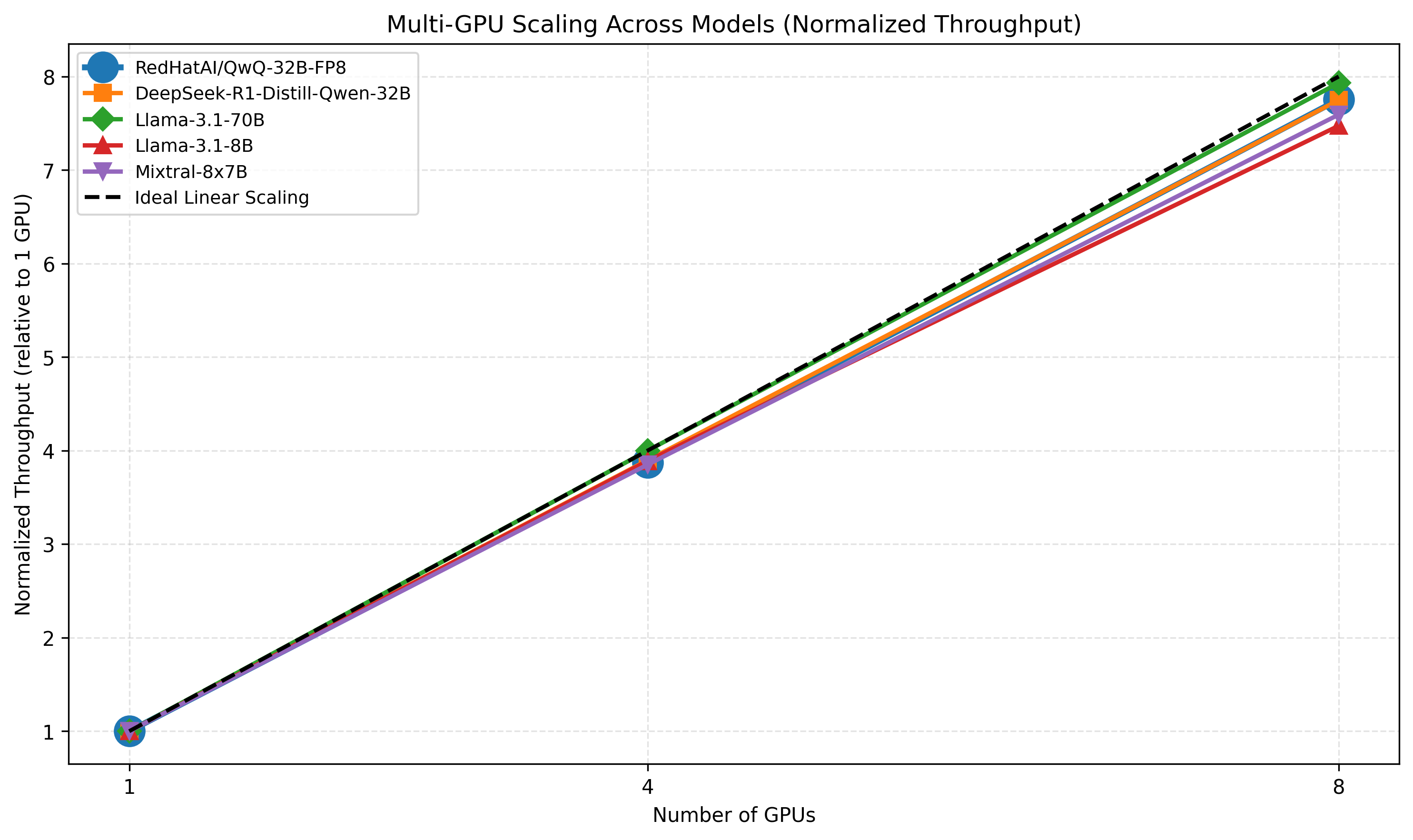
LLMBoost Multi-GPU Performance Scaling
The figure below shows the normalized throughput scaling for several representative models when running on 1, 4, and 8 GPUs.
To make models comparable, each curve is normalized to its 1-GPU throughput, so a value of 4× at 4 GPUs represents perfect linear scaling. The dashed black line represents the ideal linear-scaling curve, making it easy to see how closely LLMBoost approaches optimal parallel efficiency.
Key Takeaways
- Consistent Speedups: LLMBoost delivers faster inference compared to vLLM across most configurations
- SLO-aware Efficiency: Up to 520× more requests per second while meeting the same latency SLO
- Model Agnostic: Strong performance across various model sizes (1B to 500B+ parameters)
- Production Validated: These results reflect real-world workloads with production-grade configurations
- Near-linear Scaling: LLMBoost shows near-linear performance scaling with the number of used GPUs
Benchmark Methodology
- Throughput: Generated tokens per second across concurrent requests
- Workloads: We use the OpenOrca dataset, the same dataset used in MLPerf benchmarks, to ensure our evaluations reflect real-world production inference scenarios. (https://mlcommons.org/benchmarks/)
Why LLMBoost is Faster
LLMBoost achieves superior performance through:
- Intelligent Auto-Tuning: Automatic optimization of parallelism strategies and memory allocation
- Advanced Scheduling: Patent-pending batch scheduling algorithms
- Memory Optimization: Efficient KV-cache management and memory layout
- Hardware-Specific Optimizations: Deep integration with AMD ROCm and NVIDIA CUDA
Ready to experience these speedups yourself? Get started with our Quick Start Guide.